
xv6-lab
Lab1:XV6 和 UNIX Utilities
1.Sleep程序
实验内容及要求
为 xv6实现⽤户级 sleep 程序。您的 sleep 应该暂停⽤户指定的滴答数(ticks)。时钟周期是 xv6 内核定义的时间概念,即定时器芯⽚两次中断之间的时间。代码应该位于⽂件 user/sleep.c中。
提⽰:
在开始编码之前,请阅读的第 1 章。
将您的代码放⼊user/sleep.c中。查看user/中的⼀些其他程序 (例如user/echo.c、user/grep.c和user/rm.c)以了解命令⾏参数如何传递给程序。
将你的sleep程序添加到Makefile中的UPROGS中;完成此操作后,make qemu将编译您的程序,您将能够从 xv6 shell 运⾏它。
如果⽤户忘记传递参数,sleep 应该打印⼀条错误消息。
命令⾏参数作为字符串传递;可以使⽤atoi将其转换为整数(请参阅user/ulib.c)。
使⽤系统调⽤sleep。
请参阅kernel/sysproc.c以了解实现sleep系统调⽤的 xv6 内核代码(查找sys_sleep),请参阅user/user.h以了解可从⽤户程序调⽤sleep的 C 定义,以及user/usys.S以了解汇编代码从⽤户代码跳转到内核进⾏sleep。
sleep 的main 函数完成后 应该调⽤exit(0) 。
实验思路及解释
命令行第二个参数代表sleep 应该暂停⽤户指定的滴答数,用argc判断命令行传递的参数数量是否正确,错误打印错误消息,用atoi将传递的第二个参数转化为整数,作为sleep系统调用的参数。
实验代码
1 |
|
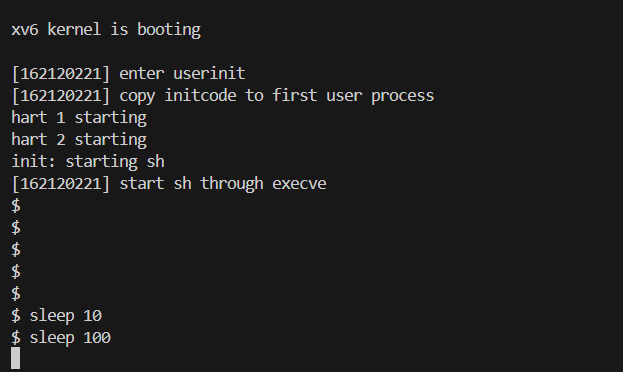
结果截图
2. pingpong程序
实验内容及要求
在xv6上实现pingpong程序,即两个进程在管道两侧来回通信。⽗进程将”ping”写⼊管道,⼦进程从管道将其读出并打印
实验思路及解释
创建两个管道p1,p2,父进程通过p1将”ping”写入管道,子进程通过p1将”ping”读出并打印
实验代码
1 |
|
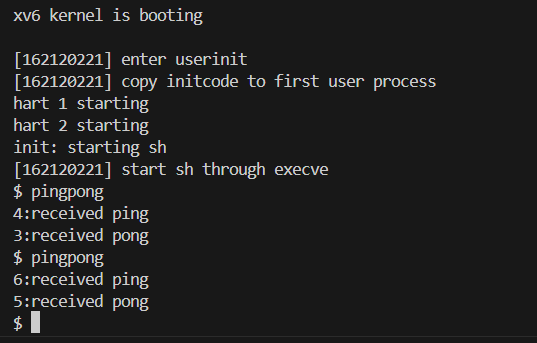
结果截图
3.primes程序
实验内容及要求
使⽤pipe和fork,完成⼀个并发的素数筛选程序,范围从2-35。其核⼼思想如下图
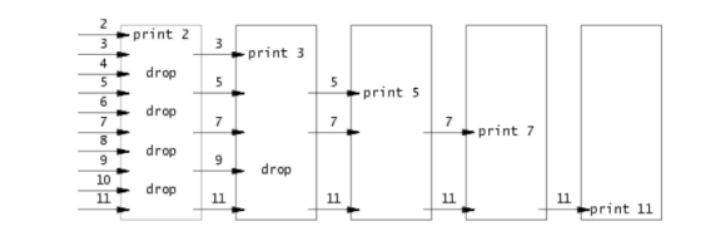 (参考http://swtch.com/~rsc/thread/):每个 block 的第⼀个数字 N ⼀定是质数,因为除了 1 跟自己,没有其他因数剩余的数字除上 N,若不可整除代表为质数的候选者,将数字向后传递重复上述步骤,直到 block 没有数字可以向后传递为止。
(参考http://swtch.com/~rsc/thread/):每个 block 的第⼀个数字 N ⼀定是质数,因为除了 1 跟自己,没有其他因数剩余的数字除上 N,若不可整除代表为质数的候选者,将数字向后传递重复上述步骤,直到 block 没有数字可以向后传递为止。
提示:
注意关闭进程不需要的文件描述符,否则程序将达到35之前用完所有系统资源,因为xv6创建⽂件描述符和进程数量有限。
管道中直接写⼊32位(4字节)最简单,无需使用格式化的ASCII I / O。
您应该仅在管道中创建流程需要。
实验思路及解释
创建一个num数组,用数组下标2-35表示2-35的整数,初始化num数组,使num[1]=0,其他元素值为1(num[0],num[1]用来做进程结束判断)。创建两条管道pp,pk,父进程将num[i](2<=i<=35)写入pp管道中,子进程从pp管道中依次读出num[i],直至读出第一个num[i]=1,并将i输出,若无num[i]=1,则表示没有其他质数未输出并将num[0]=1写入pk管道。接着子进程将num[i]置为0,将管道中剩下的数依次读出并赋值给num[j](j=i+1),如果j能整除i则表示j不是质数并将num[j]置为0,接着子进程将数组写入pk管道并写入num[1]=0,表示还有质数未输出,父进程从pk管道中读出num数组元素并读出子进程写入的标志,如果读出num[1],循环以上操作,读出num[0],结束进程。
实验代码
1 |
|
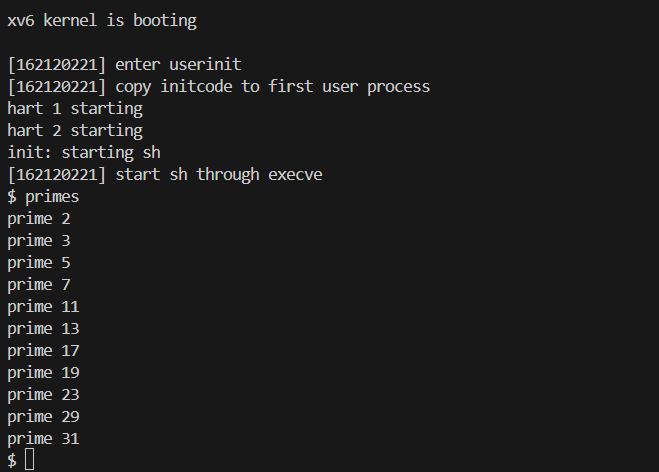
结果截图
4.XV6启动流程实验
实验内容及要求
在实验报告中解释xv6启动的整个流程。
在xv6从执⾏entry.S之后到第⼀个shell程序启动过程中的每⼀个函数中输出该函数的作用以及你的学号。
实验思路及解释
当RISC-V计算机上电时,会启动ROM(只读存储器)上的BIOS,BIOS完成硬件自检程序,读取MBR(主引导记录),执行其中的boot loader代码,它会将xv6内核加载到物理地址为0x80000000的内存中。然后,在机器模式下,中央处理器从_entry (kernel/entry.S:6)开始运行xv6。xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址。
在_entry中,会为每个CPU分配栈空间,将sp指向栈顶,使其可以执行c代码start(kernel/start.c:21)
函数start会执行一些仅在机器模式下允许的配置,然后切换到管理模式。RISC-V提供指令mret以进入管理模式,该指令最常用于将管理模式切换到机器模式的调用中返回。而start并非从这样的调用返回,而是执行以下操作:它在寄存器mstatus中将先前的运行模式改为管理模式,它通过将main函数的地址写入寄存器mepc将返回地址设为main,它通过向页表寄存器satp写入0来在管理模式下禁用虚拟地址转换,并将所有的中断和异常委托给管理模式。在进入管理模式之前,start还要执行另一项任务:对时钟芯片进行编程以产生计时器中断。清理完这些“家务”后,start通过调用mret“返回”到管理模式。这将导致程序计数器(PC)的值更改为main(kernel/main.c:11)函数地址。
在main(kernel/main.c:11)初始化几个设备和子系统后,便通过调用userinit (kernel/proc.c:212)创建第一个进程,第一个进程执行一个用RISC-V程序集写的小型程序:initcode. S (user/initcode.S:1)并转换为用户模式,它通过调用exec系统调用重新进入内核,用”/init”替换当前进程的内存和寄存器。一旦内核完成exec,它就返回/init进程中的用户空间,所以会执行 user/init.c 中的 main 函数,这个 main 函数中创建了一个子进程,这个子进程就是 shell,xv6启动完成。
实验代码
kernel/start.c
1 | void |
kernel/main.c
1 | void |
kernel/proc.c
1 | void |
user/init.c
1 | int |
结果截图
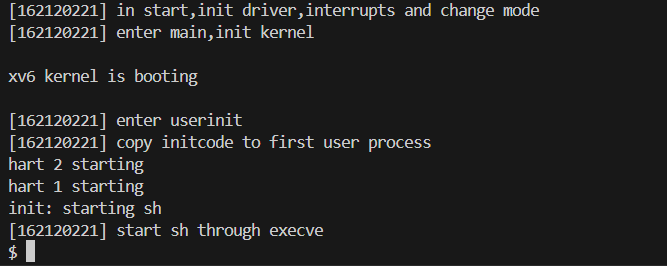
Lab 2 : GDB调试和系统调用
一、 学习如何使用 GDB 进行调试xv6
需要注意的是,在 Ubuntu 20.04.5 LTS 中,需要 安装并使用 gdb-multiarch 才可以调试 riscv64 程序。进⼊ xv6-labs-2024 文件夹中。在 终端中输入make qemu-gdb ,运行qemu 并开启调试功能。

此时再打开⼀个终端,运行:
1 | echo "set auto-load safe-path /" >> ~/.gdbinit |
Once you have two windows open, type in the gdb window:
1 | (gdb)b syscall |
b syscall 将在函数 syscall 处设置断点; c 将会运⾏到此断点时等待调试指令; layout src 将会开启⼀个窗⼝展⽰调试时的源代码; backtrace 将会打印堆栈回溯 (stack backtrace)。
如图

回答第⼀个问题:
1 | Looking at the backtrace output, which function called syscall? |
syscall()的调用者为kernel/trap.c文件中的usertrap()函数
输入几个 n 命令,使其执行 struct proc *p = myproc(); 在gdb中输⼊ p /x *p 打 印 *p 的值,这是是⼀个 proc 结构体,定义在 kernel/proc.h 中。

回答第二个问题:
1 | What is the value of p->trapframe->a7 and what does that value represent? (Hint: look user/initcode.S , the first user program xv6 starts.) |
输入命令查看 p->trapframe->a7 的值。

得到 a7 的值为 7 。根据参考教材book-riscv-rev3.pdf第二章和 user/initcode.S 中的代码可知,这个 a7 寄存器中保存了将要执行的系统调用号。这里的系统调用号为 7,在 kernel/syscall.h 中可以找到,这个系统调用为 SYS_exec 。
系统调用运行在内核模式(kernel mode),可以通过 Supervisor Status Register ( sstatus ) 来查看当前CPU 的状态。在gdb中输入 p /x $sstatus 。具体参看官 方RISC-V privileged instructions 文档 4.1.1 章节。
回答第三个问题:
1 | What was the previous mode that the CPU was in? |
输入 GDB 命令来查看 sstatus 寄存器。通过 p/t 以二进制打印。
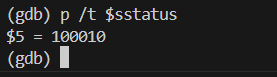
官方文档对sstatus寄存器的解释如下。
SPP 位指示进入管理员模式之前 hart 执行的特权级别。 当采取陷阱时,如果陷阱源自用户模式,则 SPP 设置为 0,否则设置为 1。 当执行 SRET 指令(见第 3.3.2 节)从陷阱处理程序返回时,如果 SPP 位为 0,则特权级别设置为用户模式,如果 SPP 位为 1,则设置为超级用户模式; 然后将 SPP 设置为 0。
根据 sstatus 的二进制值 100010 可知,SPP 位是 0,那么在执行系统调用陷入内核之前的特权级别就是 user mode。
在后续的实验中,我们编写的代码可能会使内核崩溃(panic)。如下图所示,替换 syscall() 函数中的 num = p->trapframe->a7; 为 num = * (int *) 0; ,然后运行make qemu 。
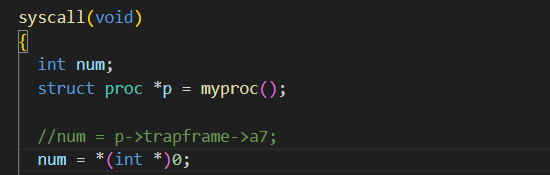
这样会看到⼀个 panic 信息,类似下图:
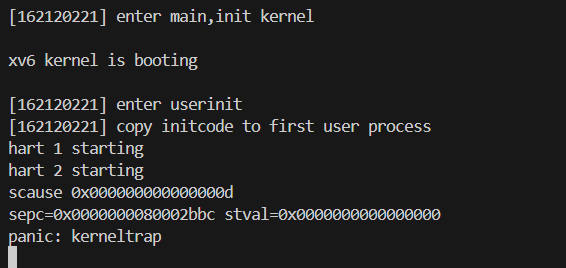
这里的 sepc 指代内核发生panic 的代码地址。可以在 kernel/kernel.asm 中查看编译 后的完整内核汇编代码,在其中搜索这个地址既可以找到使内核 panic 的代码。注 意:sepc 的值不是固定不变的。在这里是 0x0000000080002bbc ,所以我 在 kernel/kernel.asm 中搜索 80002bbc。
回答第四个问题:
1 | Write down the assembly instruction the kernel is panicing at. Which register corresponds to the variable num? |

可知这条汇编代码代表将内存中地址从 0 开始的一个字 word (2 bytes) 大小的数据加载到寄存器 s2 中。
回答第五个问题:
1 | Why does the kernel crash? Hint: look at figure 3-3 below; is address 0 mapped in the kernel address space? Is that confirmed by the value in scause above? |
再次运行虚拟器和 GDB 调试。将断点设置在发生panic 处。
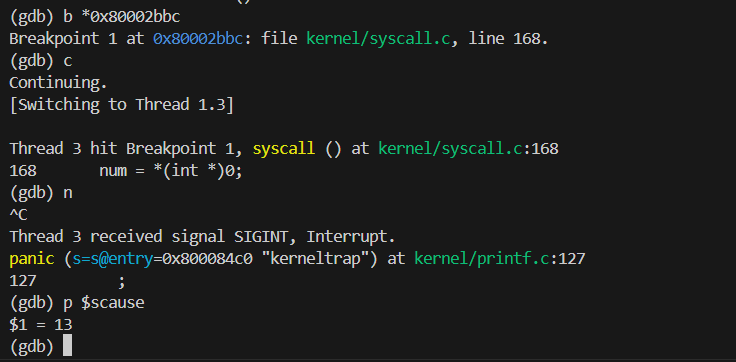
查看 scase 寄存器,它代指内核 panic 的原因。如上图,scase寄存器的值为13。
查看参考教材可知

发现是Load page fault。证实了内核崩溃的原因,因为我们修改:num = * (int *) 0;即把0看做一个指针,然后去0地址处取值,而0地址没有映射到内核地址空间,所以 Load page fault。根据参考教材book-riscv-rev3.pdf
上述 scuase 指明了内核 panic 的原因。但是有时候我们需要知道,是哪⼀个用户程 序调用syscall 时发生了 panic。这可以通过打印 proc 结构体中的 name 来查看。重新启动 qemu 和 gdb。

回答第六个问题:
1 | What is the name of the binary that was running when the kernel paniced? What is its process id ( pid )? |
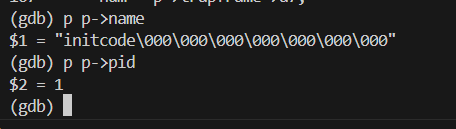
正在运行的二进制文件名为initcode , pid 为 1。
二、增加系统调用trace
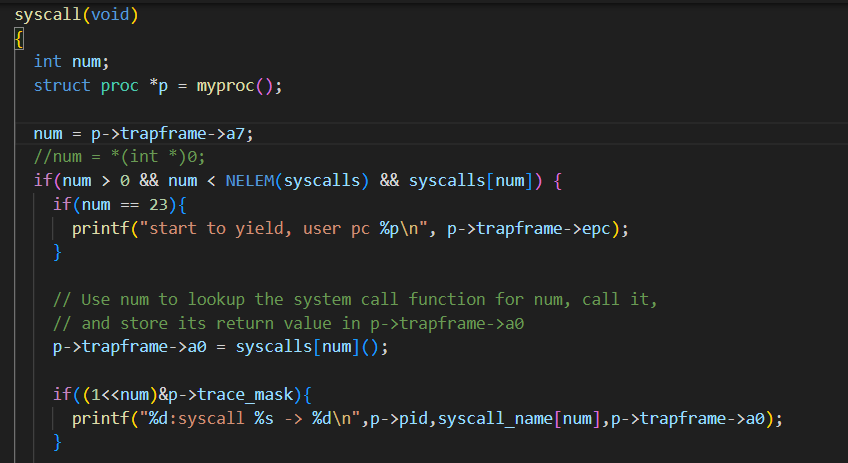
在本实验中,添加⼀个系统调用跟踪功能,这对后面的实验会有帮助。 要求:创建⼀个名为 trace 的系统调用来启用跟踪。该系统调用接受⼀个参数,该参数为⼀个掩码(mask),不同的比特位用于指定需要跟踪的系统调用。例如,要跟踪 fork系统调用,调用trace(1 << SYS_fork),其中SYS_fork是来自kernel/syscall.h的系统调用号。修改xv6内核,⼀旦系统调用号在mask中设置,在每个系统调用即将返回时打印⼀行。该行应包含进程ID、系统调用的名称和返回值(不需要打印系统调用的参数)。 trace 系统调用应该为调用它的进程及其创建的任何子进程启用跟踪,不应影响其他进程。
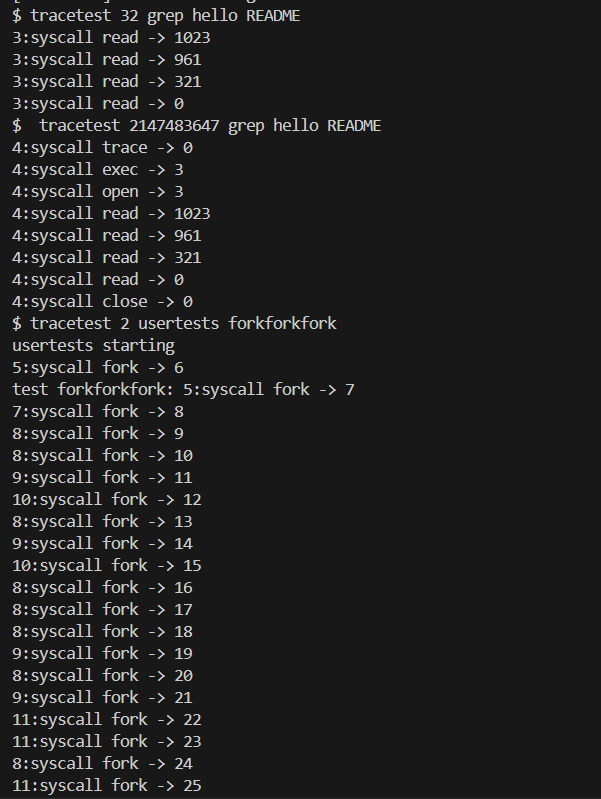
We provide a tracetest user-level program that runs another program with tracing enabled (see user/tracetest.c). When you’re done, you should see output like this:
1 | $ tracetest 32 grep hello README |
提示:
将 $U/_tracetest 添加到 Makefile 的 UPROGS 中。
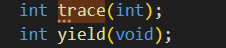
运行make qemu ,将会发现无法编译 user/tracetest.c ,这是因为编译器无法找到 这个 trace 系统调用的定义。在 user/user.h 中添加这个系统调用的函数原型;
在 user/usys.pl 中添加⼀个 entry ,它将会⽣成 user/usys.S ,里面包含真实的汇编代码,它使用RISC-V 的 ecall 指令陷入内核,执行系统调用;
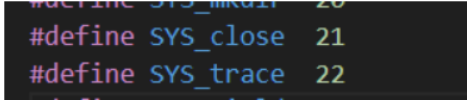
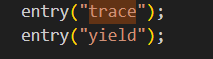
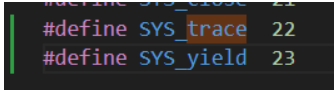
在kernel/syscal.h 中添加⼀个系统调用号。做完这些, make qemu 就不会报错了。
在 kernel/sysproc.c 中添加⼀个 sys_trace() 函数作为系统调用。它通过将它的参数保存到 proc 结构体(kernel/proc.h )中的新变量中,来实现其功能。
从用户空间获取系统调用参数的函数位于 kernel/syscall.c 中,用法例子见kernel/sysproc.c 。
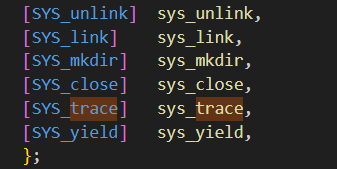
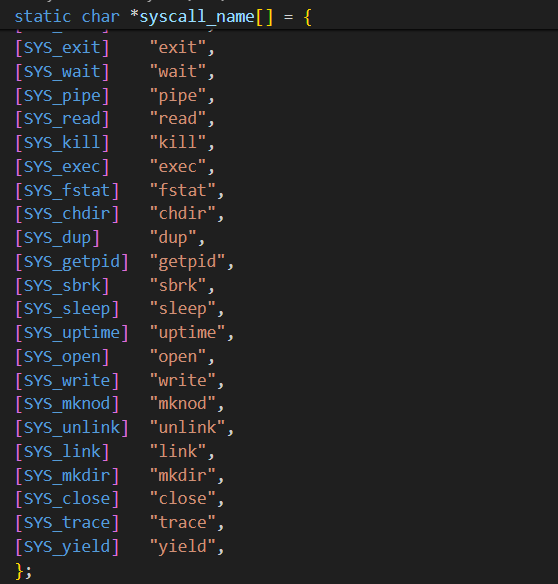
修改 fork() (位于 kernel/proc.c ),从父程序拷贝追踪掩码(mask)到子进程。 在 kernel/syscall.c 修改 syscall() ,以此来打印系统调用trace。你需要添加⼀个 系统调用名字数组,用来索引。
修改的文件如下
Makefile
user/user.h
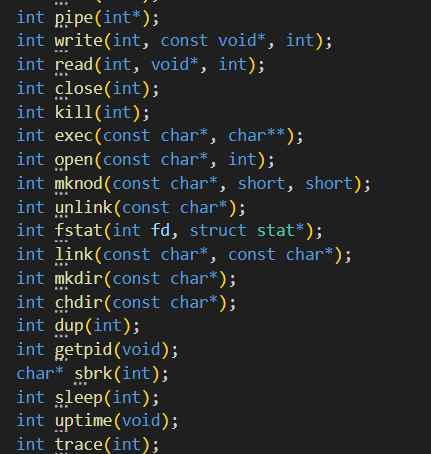
user/usys.pl
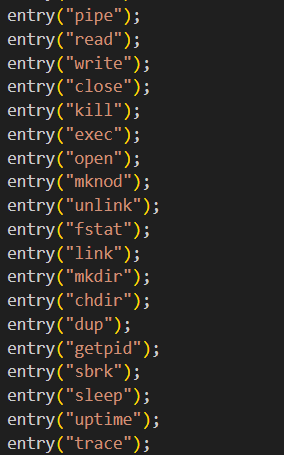
kernel/proc.h
kernel/proc.c

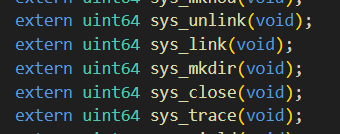
kernel/syscall.h
kernel/syscall.c
kernel/syspro.c
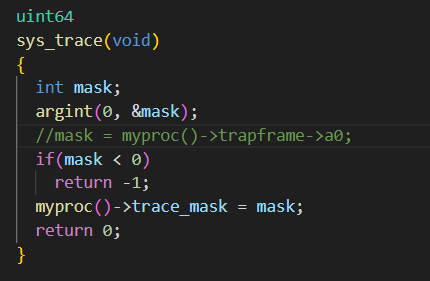
既然每个系统调用都要进入syscall函数,我们只需要在syscall函数中埋点就可以了,要跟踪指定的系统调用,比如跟踪系统调用号为num的某种系统调用,那么mask就是1<<num,进入syscall()函数后,要检查mask的第num位是不是1,是的话就进行打印相关信息。但是如何将 mask 函数传入 syscall 中呢?mask是属于 trace 的参数,是不能直接传递到syscall()这个公共位置的,题目提示可以把mask作为proc的一个字段保存到proc中。
实现结果如下
三.增加系统调用yield
在该任务中,你需要实现⼀个新的系统调⽤ yield ,它可以使当前进程让出CPU,从而使CPU可以调度到别的进程。当然,该进程只是暂时被挂起,根据我们在课上学过的进程调度算法,如Round-Robin即时间片轮转调度算法,该进程很快便会再次被 CPU调度到,从而从yield系统调用中返回,继续执行该进程后面的代码。另外我们的实验还有些额外要求。 具体来说,当调用yield 系统调用时:
1. 需要打印此时用户态的pc值,也就是陷⼊内核的那条指令地址,即 ecall 指令的地 址,详情见系统调用的接口中提到的系统调用步骤,按如下格式打印: `start to yield, user pc 0x???????` 也就是在某个位置,添加上这样⼀句代码:
1
printf("start to yield, user pc %p\n", pc);
2. 将当前进程让出CPU,从而调度到别的进程。 实验提供了⼀个 yieldtest 用户态测试程序
(见user/yieldtest.c)。
完成任务后,你可以在xv6中运行 yieldtest 程序,不过有以下几点需要注意:
(1) 需要⼿动将 yieldtest 添加进Makefile中进行编译,即找到 UPROGS 变量,添加⼀行:

(2) 该任务测试的时候需要 设置CPU的数量为1 ,即使使用如下命令运行xv6: make qemu CPUS=1 正确完成任务后 yieldtest 的输出如下:
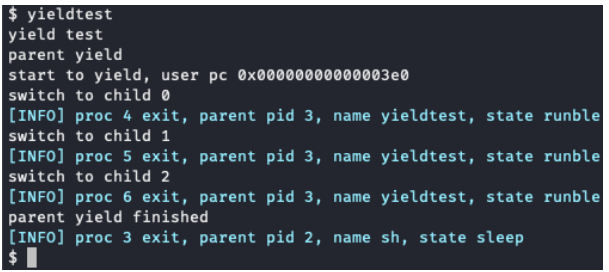
修改文件如下
Makefile
user.h
usys.pl
kernel/syscall.h
kernel/syscall.c
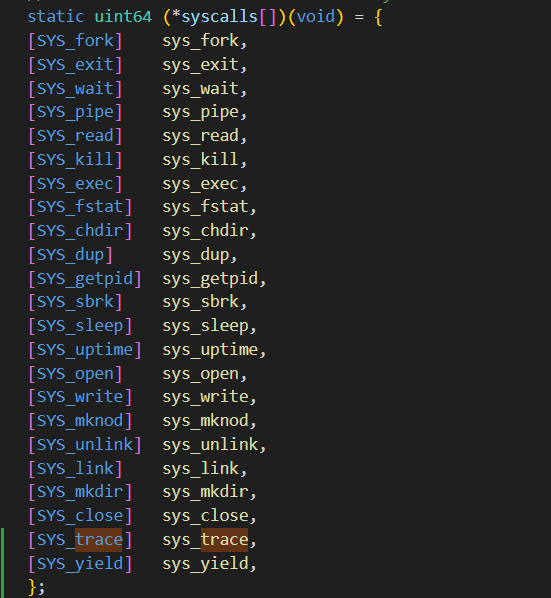
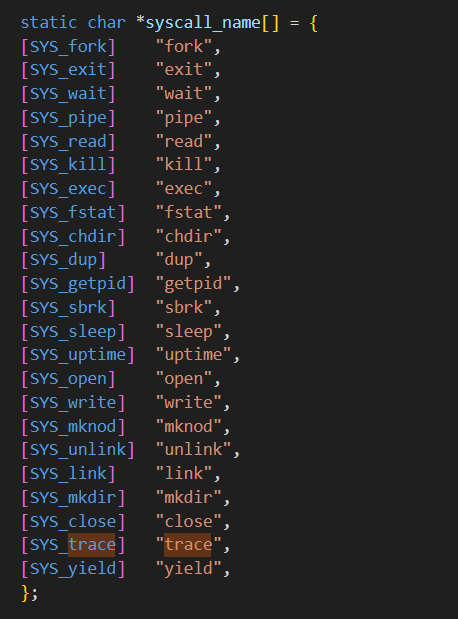

kernel/syspro.c
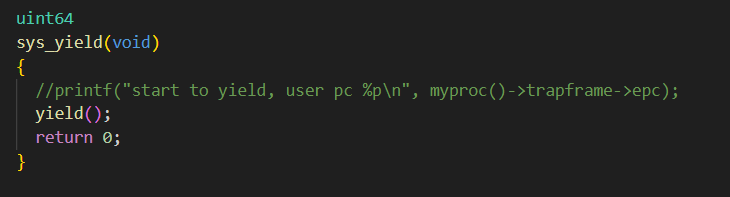
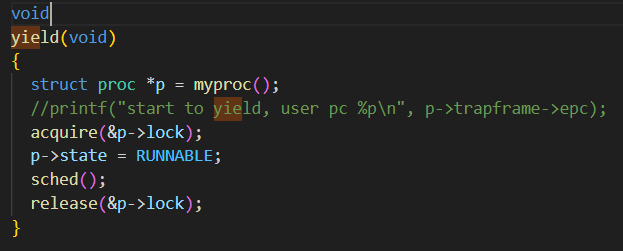
yield函数实现如下(在kernel/proc.c中)
实验结果
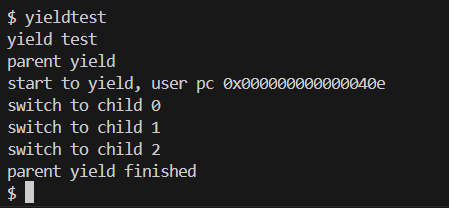
因为最底层实现yield()(kernel/proc.c)已经写好,所以只需添加系统调用即可。
四、实验总结与感想
了解了如何使用gdb来调试xv6的代码,也学会了如何在xv6中添加系统调用,提高了我对操作系统学习的兴趣,为之后的实验打下基础。
Lab 3 : 多线程
一、 用户态线程的上下文切换机制
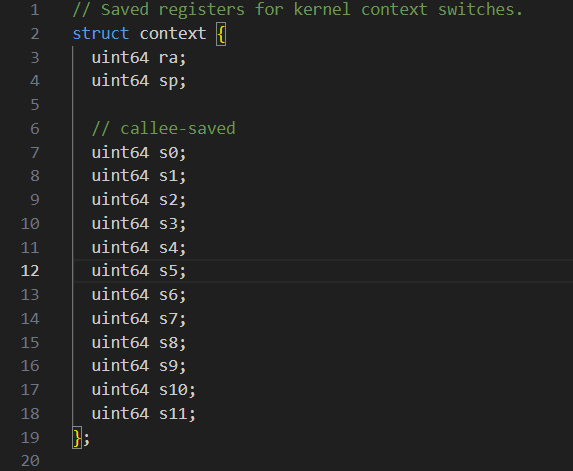
在本练习中,你将为用户级线程设计上下⽂切换机制,然后加以实现。 xv6 提供了两个文件 user/uthread.c 和 user/uthread_switch.S ,首先阅读这两个文件,尤其是uthread.c ,知道它是如何运行的。 uthread.c 包含用户级线程包的大部分内容,以 及三个简单测试线程的代码。但其中缺少⼀些创建线程和在线程间切换的代码。 根据 xv6-book ,切换线程需要保存和恢复 CPU 上下文(也就是寄存器)的相关信息, 所以在 struct thread 中,需要有 CPU 寄存器的相关信息,你⼿动添加它。我们不需要保存全部的寄存器,只需要保存 callee-save registers ,可以参考 kernel/proc.h 中相关的内容。
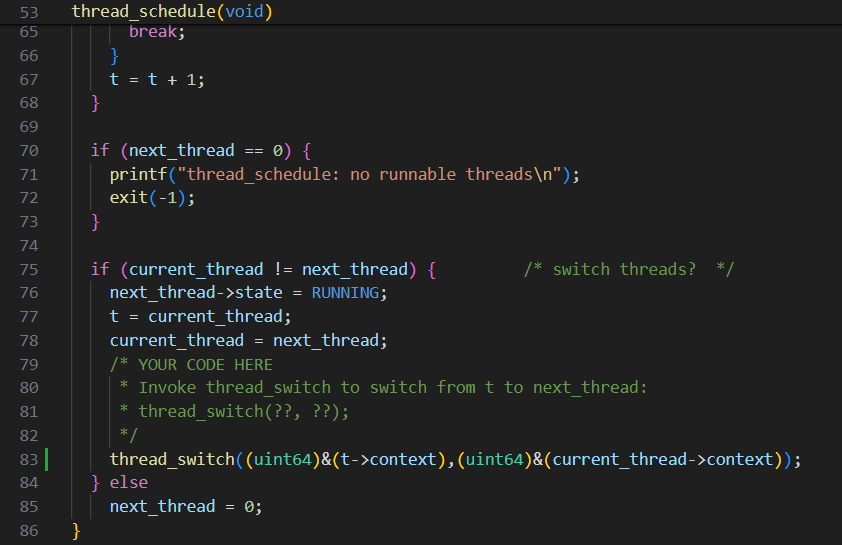
你需要为 user/uthread.c 中的 thread_create() 和 thread_schedule() 以及 user/uthread_switch.S 中的 thread_switch 添加代码。⼀个⽬标是确保 thread_schedule() ⾸次运⾏给定线程时,该线程在⾃⼰的堆栈上执⾏传递给 thread_create() 的函数。另⼀个⽬标是确保线程切换( thread_switch )保存被切换线程的寄存器,恢复被切换线程的寄存器,并返回到后⼀个线程指令中最后离开的位置。此外,同学们需要在 thread_schedule 中添加对 thread_switch 的调⽤;你可以给 thread_switch 传递任何你需要的参数,但⽬的是从线程 t 切换到 next_thread 。 代码中,需要同学们修改多个地⽅已经标识,如下: // YOUR CODE HERE
完成后,仿照之前添加⽤户程序的⽅法,在 Makefile 的 UPROGS 中增加 uthread 程 序。然后,在 xv6 上运⾏ uthread 时应该会看到如下输出(三个线程的启动顺序可能 Lab 3 :多线程不同):
1 | $make qemu |
这些输出来⾃三个测试线程,每个线程都有⼀个循环,打印⼀⾏,然后将 CPU 移交给 其他线程。
实现
可以根据提示查看kernel/proc.h中context进行仿写
kernel/proc.h
user/uthread.c
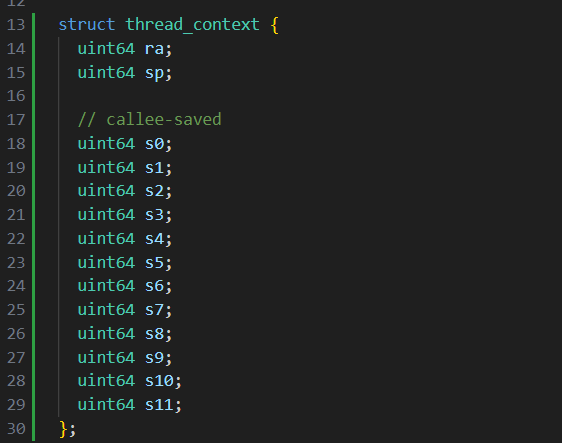
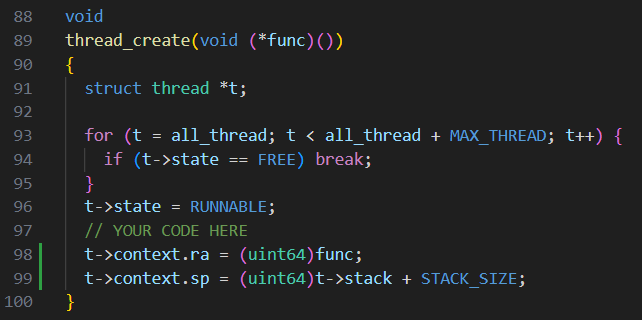
为了确保 thread_schedule()首次运行给定线程时,使该线程在自己的堆栈上执行传递给 thread_create() 的函数,在thread_create中可以将函数地址存入ra寄存器中,并通过修改sp开辟出线程自己的栈空间
user/uthread.c
接着为了确保线程切换( thread_switch )保存被切换线程的寄存器,恢复被切换线程的寄存器,并返回到后⼀个线程指令中最后离开的位置,可仿写kernel/switch.S文件内容
kernel/switch.S

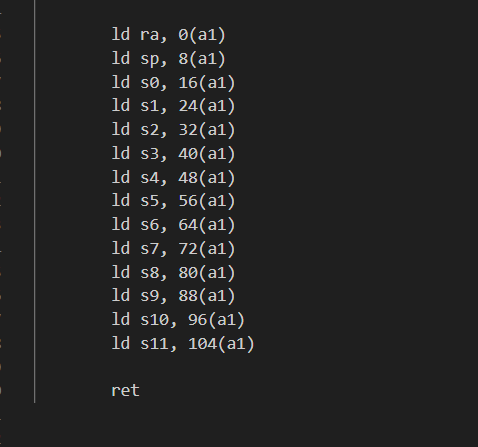
user/uthread_switch.S
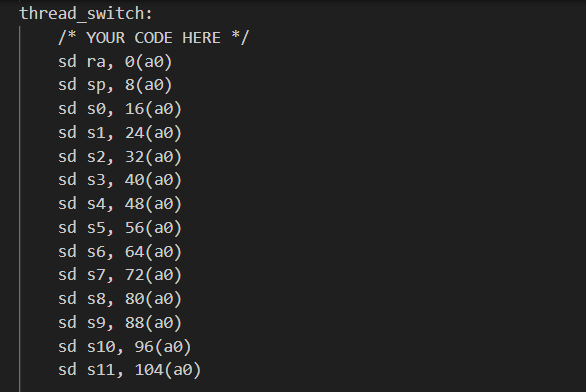
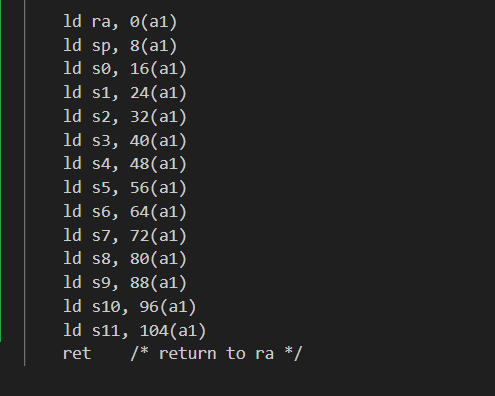
最后在thread_schedule中加上对thread_switch的调用
user/uthread.c
实验结果
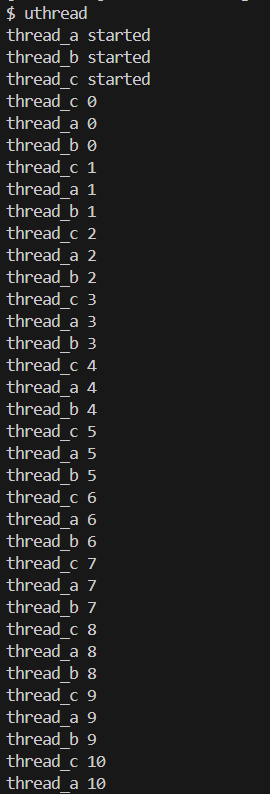
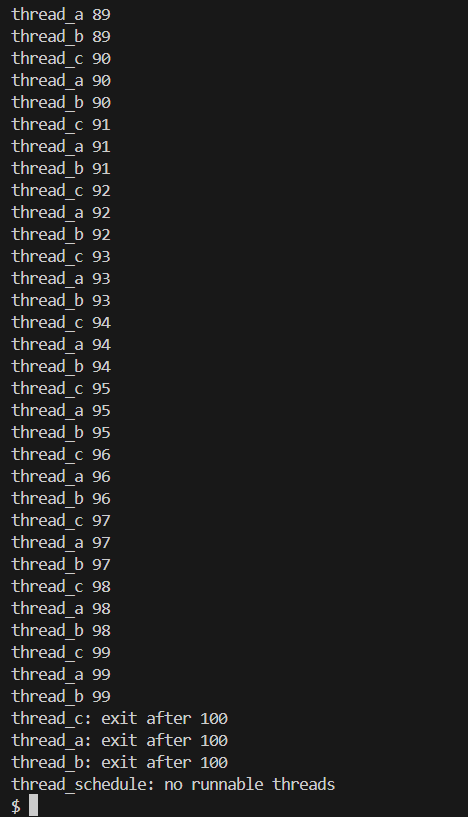
二、使用多线程编程
需要修改的⽂件存储在 notxv6 ⽬录下,⽂件 notxv6/ph.c 包含⼀个简单的哈希表,在单 线程中使⽤时是正确的,但在多线程中使⽤时则不正确。在 xv6 主⽬录下,键⼊ 2 以下内容:
1 | $ make ph |
ph 的参数指定了在哈希表上执行 put 和 get 操作的线程数。运行⼀段时间后,将产生类似下面的输出:
1 | 100000 puts, 3.991 seconds, 25056 puts/second |
你看到的数字可能与此示例输出结果不同,这取决于你的电脑速度有多快、是否有多 个内核以及是否忙于其他事情。 ph 运行了两个基准测试。首先,它通过调用 put 向哈希表中添加大量键值,并打印出所达到的速度(单位为每秒的输⼊次数)。然后, 它调用 get 从散列表中获取键值,并打印出本应在散列表中的键值数量(本例中为 零),以及每秒获取的键值数量。 接下来你可以给它⼀个大于 1 的参数,让它同时从多个线程使用哈希表。尝试运行 ph 2 :
1 | $ ./ph 2 |
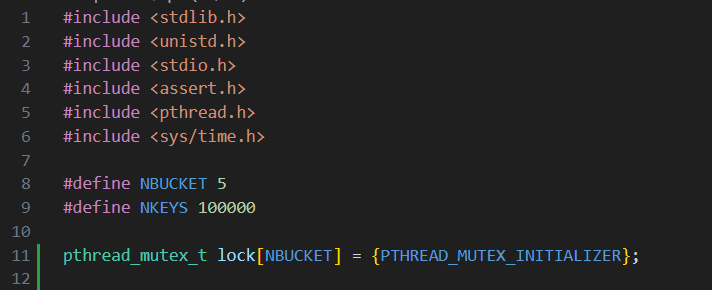
ph 2 输出的第⼀⾏显⽰,当两个线程同时向哈希表中添加条⽬时,它们的总插⼊速率为每秒 53044 次。这⼤约是运⾏ ph 1 的单线程速度的两倍。这是我们所能期望的 (即两倍的内核在单位时间内产⽣两倍的⼯作量)。不过,两⾏ “16579 keys missing” 的字样表明,哈希表中应该存在的⼤量键值并不在其中。也就是说, puts 本应将这些键添加到哈希表中,但却出了差错。 为了避免出错,可在 notxv6/ph.c 代码的 put 和 get 中插⼊枷锁和解锁语句,这样在两个线程中丢失的键数始终为 0 。相关的 pthread 调⽤如下:
1 | pthread_mutex_t lock; // declare a lock |
在某些情况下,并发的 put() 在哈希表中读写的内存没有重叠,因此不需要锁来相互保护。你能否修改 ph.c ,利⽤这种情况来提⾼某些 put() 的并⾏速度?提⽰:为每个哈希桶加锁。
实现
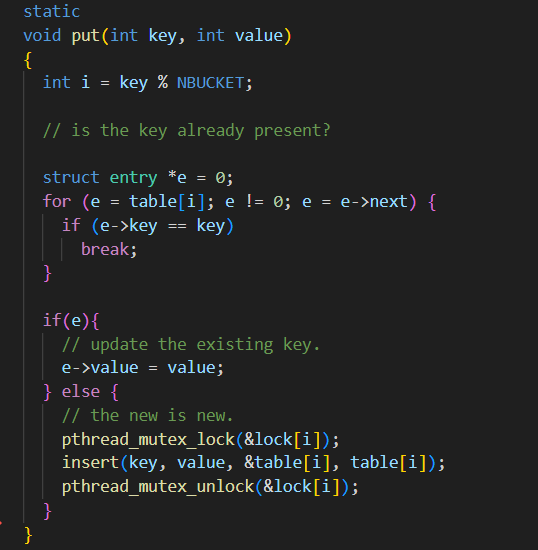
键数的丢失是因为在对哈希表进行插入操作的时候未加锁导致可能有多个线程插入键值对到同一哈希表同一位置,因此会有丢失。所以只要在插入键值对之前加锁,插入完后释放锁即可。考虑到在某些情况下,并发的 put() 在哈希表中读写的内存没有重叠,因此不需要锁来相互保护,可为每个哈希桶分配一个锁。
notxv6/ph.c
实验结果


三 、 Barrier 机制
在本任务中,同学们将实现⼀个 Barrier 机制,可以让所有线程阻塞,直到所有线程都到达这个位置,然后继续运⾏。你将使⽤ pthread 条件变量,它是⼀种序列协调技术,类似于 xv6 的 sleep 和 wakeup 。该任务使⽤ Linux 系统,⽽不是在 xv6 和 qemu 上完成⽂件 notxv6/barrier.c 包含了不完整的 Barrier 实现。
1 | $ make barrier |
参数 2 指定了在 barrier 上同步的线程数(在 barrier.c 中为 nthread )。每个线程执⾏⼀个循环。在每个循环迭代中,⼀个线程调⽤ barrier() 然后休眠⼀个随机的微秒数。断⾔触发的原因是⼀个线程在另⼀个线程到达 barrier 之前离开了屏障。所需的⾏为是每个线程阻塞 barrier() 直到所有 n 个线程都调⽤了 barrier() 。 该任务除了上述 pthread 调⽤外,还需要⽤到:
1 | pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up |
实现
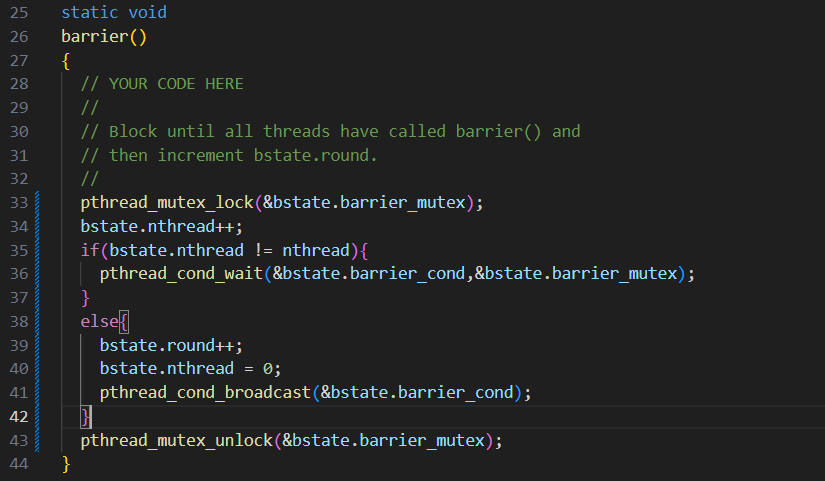
根据题目提示,为了可以让所有线程阻塞,直到所有线程都到达同一位置,然后继续运⾏,可以在barrier中阻塞线程直至达到barrier的线程数达到所设线程数,具体实现如下:
notxv6/barrier.c
实验结果

四、实验总结与感想
了解了如何用户级线程的上下文切换机制,学习了如何使用多线程编程和barrier机制,为以后的实验学习打下基础。
Lab 4 : 页表
一、 加速系统调用
⼀些操作系统(如 Linux )通过在⽤户空间和内核之间共享只读区域中的数据来加快 某些系统调⽤的速度。这样⽤户程序就不⽤陷⼊内核中,⽽是直接从这个只读的空间 中获取数据,省去了⼀些系统开销,加速了⼀些系统调⽤。你的任务是在 xv6 中的 getpid() 系统调⽤中实现这⼀优化。 我们先来看⼀张 xv6 如何管理虚拟内存的图
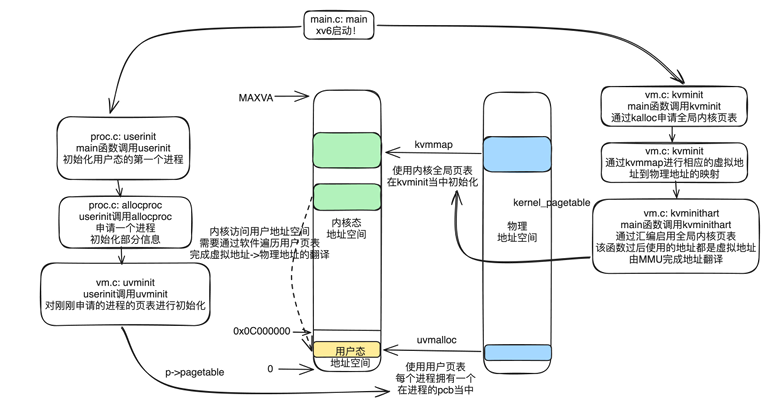
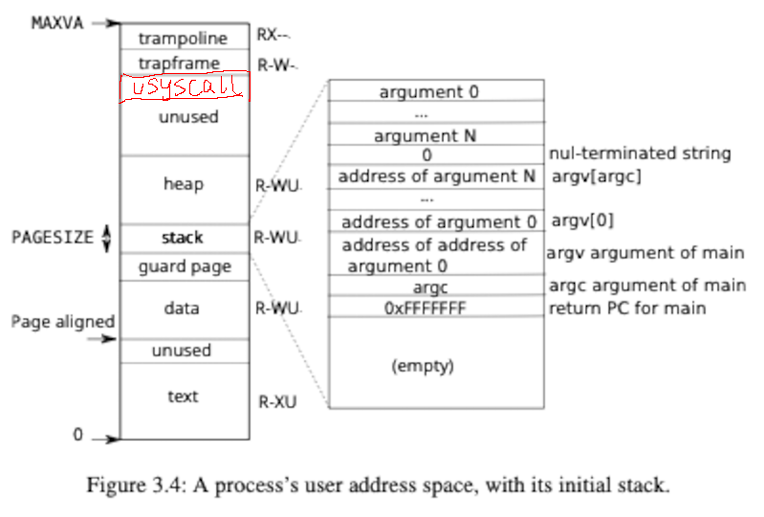
xv6 在初始化时会调⽤ kvminit 完成全局内核⻚表的初始化,使⽤ kvminithart 启⽤刚 刚初始化的内核全局⻚表。然后 xv6 还会调⽤ userinit ,初始化第⼀个⽤户态进程 initproc 。在 userinit 当中,会调⽤ allocproc 完成进程的申请(实际上就是申请和填 写进程的 PCB ),在然后会调⽤ uvminit 完成⽤户进程的⻚表( ⽤户⻚表 )的初始化。 xv6 有两个⻚表(全局内核⻚表和⽤户⻚表)都是完成虚拟地址到物理地址的映射的记录 ,但是为了安全起⻅,操作系统在内核态当中不能直接访问⽤户态的地址空间,所以内核态不能直接转化⽤户态的虚拟地址,需要遍历⽤户态的⽤户⻚表(在 PCB 当 中),完成虚拟地址( va )到物理地址( pa )的转换。 在 xv6 中,⽤户程序运⾏和内核运⾏的时候,使⽤的是不同的⻚表。如下图所⽰,⽤户程序⻚表仅包含⾃⾝的代码和数据的虚实地址映射,内核代码和数据不包含在内。
其代码实现在 kernel/exec.c 中, exec 使⽤ proc_pagetable 分配了 TRAPFRAME 的⻚表映射,然后⽤ TRAMPOLINE 和 uvmalloc 来为每个 ELF 段分配内存及⻚表映射,并⽤ loadseg 把每个 ELF 段载⼊内存。当进程申请更多内存的时候, xv6 ⾸先⽤⼀个物理⻚。然后调⽤ kalloc 分配 mappages 函数把这个物理⻚的 PTE 加到进程的⻚表⾥。 xv6 会设置该 PTE 对应的标志位 (W,X,R,U,V) 。
本任务需要完成的是:如上图所⽰,当创建每个进程时,在 memlayout.h 中新增加 USYSCALL 处映射⼀个只读⻚⾯。在该⻚⾯中,存储⼀个 struct usyscall (也在 memlayout.h 中定义),⽤于存储当前进程的 PID 。这样,⽤户进程在需要获取⾃⾝ PID 时就可以不⽤系统调⽤(上下⽂切换),⽽直接从 USYSCALL 处获取。在实验 中, ugetpid() 将在⽤户空间侧提供,并⾃动使⽤ USYSCALL 映射。
实现过程
根据提示在memlayout.h中增加USYSCALL的宏定义,因为USYSCALL在trapframe的下方,而trapframe大小为一页,因此可以确定USYSCALL为TRAPFRAME - PGSIZE
memlayout.h

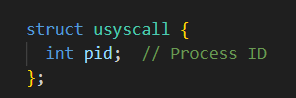
在proc.h中添加一个usyscall结构体变量*usys,而usycall结构体存放进程的pid
proc.h
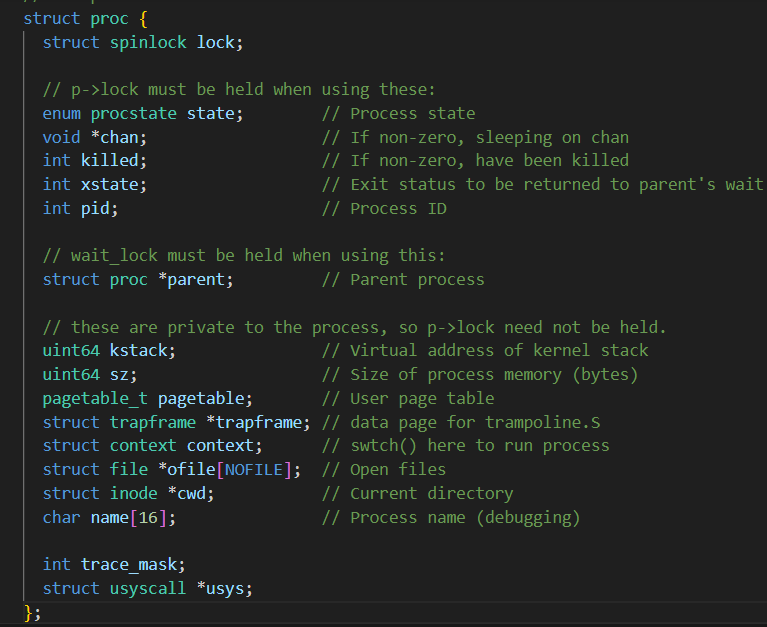
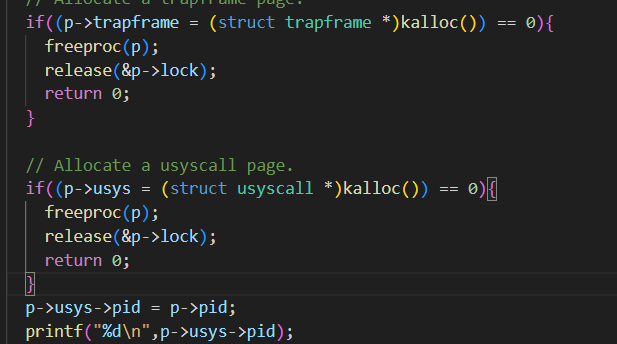
接着我们可以根据第一幅图,在proc.c的allocproc看到userinit申请一个进程的部分初始化信息,仿写trapframe页的分配,添加以下代码
1 | // Allocate a usyscall page. |
proc.c
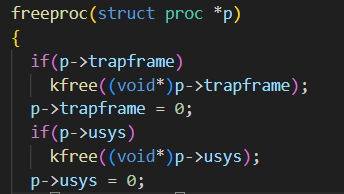
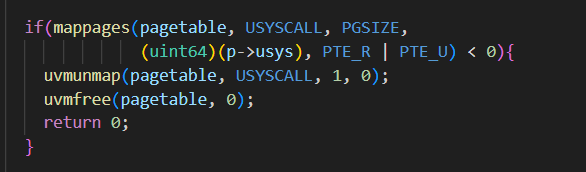
再接着完善freeproc函数中对usyscall页的释放,在proc_pagetable函数中添加对usyscall页的映射,将进程p的用户系统调用(usyscall)页映射到其页表pagetable中的USYSCALL虚拟地址处,在proc_freepagetable函数取消页表中usyscall页的映射
proc.c
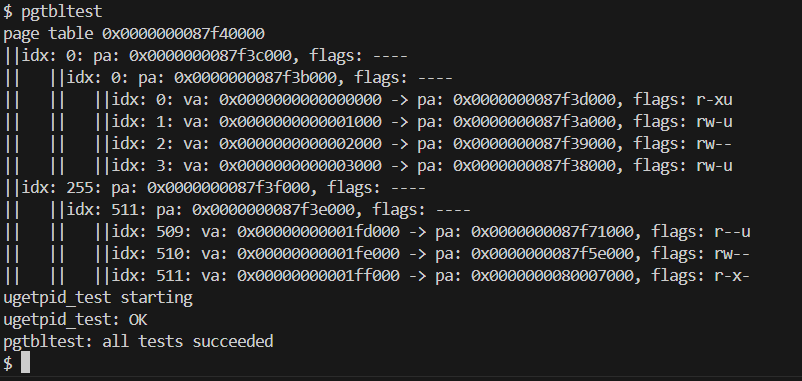
实验结果
输入pgtbltest,测试通过
二、打印页表
1 )打印函数定义 void vmprint(pagetable_t pgtbl) 该函数将获取⼀个根⻚表指针作为参数,然后打印对应的⻚表数据。 函数的使⽤位置 :注意!该函数⼀定要插⼊在 exec() 逻辑结束的末尾,来打印第⼀个进程或刚载⼊程序的⻚表数据。在开发过程中,你可以插⼊到其他的地⽅,但是最后 ⼀定只保留这⼀个地⽅的函数使⽤。 exec.c 中的返回 argc 之前插⼊ 在 的⻚表。其中, vmprint() 函数,以输出第⼀个进程或刚载⼊程序 vmprint() 函数的⼊参可以根据你⾃⼰的设计来填⼊。
exec.c
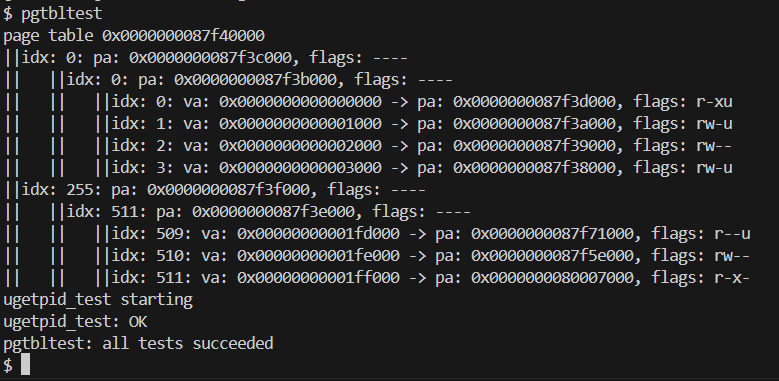
2 )结果⽰例 当输入命令后,函数会得到以下的输出:

首先遍历顶级页表,检查当前页表项是否有效(PTE_V位是否为1),找到次级页表,打印第一级页表项的信息,接着遍历第二级页表,检查当前页表项是否有效,找到叶子页表,打印第二级页表项的信息,最后遍历叶子页表,打印页表项的信息,包括虚拟地址、物理地址和标志位
exec.c
1 | void printFlag(pte_t pte) |
实验结果
三、实验总结与感想
了解了如何加速系统调用和打印页表,为之后的操作系统学习打下基础。
Lab 5 : 文件系统
一、 大文件功能的支持
任务:当前的 xv6 ⽂件被限制在 268 个块内, 每⼀块 1024 字节( BSIZE 在 xv6 中设置为 1024 ),这个限制由于 xv6 的 inode 结点包含 12 个直接块号,⼀个⼀级间接块号,间接 块号可以存储 256 个数据块直接块号,因此总共是 12 + 256 = 268 块。你将修改 xv6 ⽂件系统代码,通过引⼊⼆级间接块( doubly-indirect block )来增加⽂件⼤⼩的最 ⼤值。每⼀个⼆级间接块包括 256 个⼀级间接块地址,每个⼀级间接块⼜可以存储 256 个数据块地址,因此最⼤⽂件可以达到 65803 块( 256 * 256 + 256 + 11 块, 11 个而不是 12 个,因为我们将牺牲⼀个直接数据块的编号来使⽤双向数据块) bigfile 命令可以创建最⻓的⽂件,并报告⽂件⼤⼩:
1 | $ bigfile .. |
测试失败的原因是 bigfile 希望能创建⼀个有 65803 个块的⽂件,但未修改的 xv6 限制⽂件只能有 268 个块。
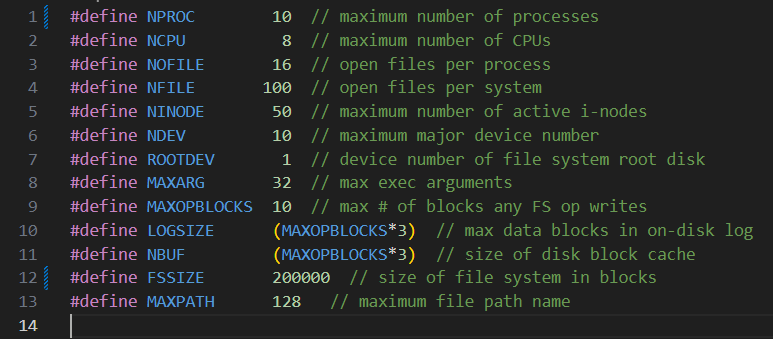
1 | 在开始本实验之前,将 kernel/param.h ⽂件中相应位置改为如下值: |
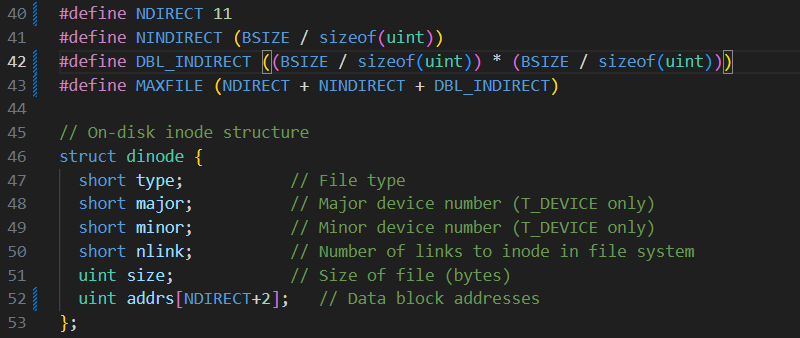
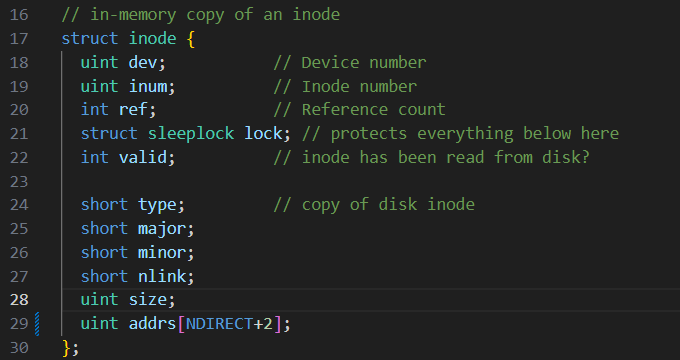
1 )修改 xv6 ⽂件系统代码 kernel/fs.h 和 分别修改 inode 都⽀持⼀个⼆级间接块。 kernel/file.h 中的 struct inode 与 struct dinode 结构,使每个 inode 都⽀持⼀个⼆级间接块。
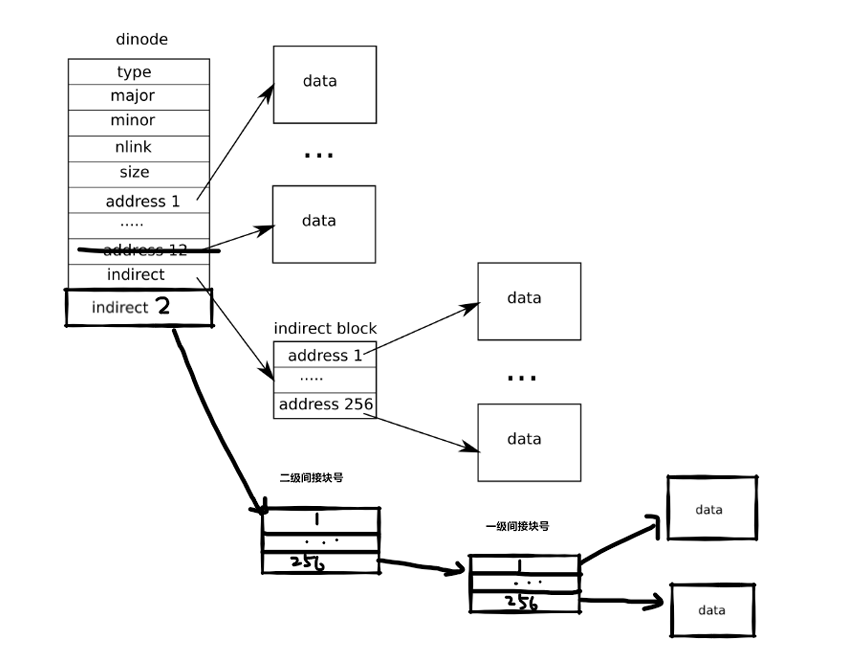
2 )修改 fs.c/bmap() 在磁盘上查找⽂件数据的代码位于 fs.c 中的 bmap() 中。在写⽂件时, bmap() 会根据需要分配新块来保存⽂件内容,并根据需要分配间接块来保存块地址。其中, bn 参 数是 “ 逻辑块编号 “ ,也就是⽂件中相对于⽂件起始位置的块编号。⽽ ip→addrs[] 中 的块号和 bread() 的参数是磁盘块号。你可以将 bmap() 视为将⽂件的逻辑块编号映射到磁盘块编号。
修改 bmap() ,使其除了实现直接块和⼀级间接块外,还能实现⼆级间接块。注意:不 能改变磁盘 inode 的⼤⼩。 ip→addrs[] 的前 11 个元素应该是直接块;第 12 个应该是 ⼀级间接块;第 13 个应该是新的⼆级间接块。
3 ) 修改 fs.c/itrunc() 有增加映射就有删除映射, itrunc() ⽤于删除整个⽂件内容,则需要查找 inode ,删除 所占有的所有数据块,包括⼀级间接块、⼆级间接块。Make sure itrunc() frees all blocks of a file, including double-indirect blocks.
最后,执⾏ make qemu CPUS=1 ,运⾏ bigfile 程序。当 bigfile 写⼊ 65803 个块成功 运⾏时,本任务就完成了。
实现过程
1)根据提示将param.h中的两个宏定义修改
kernel/param.h
修改 kernel/file.h 中的 struct inode 与 struct dinode 结构,使每个 inode 都⽀持⼀个⼆级间接块,根据提示用一个直接块充当二级间接块,并定义二级间接块的块数大小,修改最大文件的块数大小,因为inode是dinode的内存副本,所以只要将dincode中做的修改在file.h中再做一遍就行
kernel/fs.h
kernel/file.h
2)修改bmap函数,使其除了实现直接块和⼀级间接块外,还能实现⼆级间接块。用inode中addrs数组的第十三个元素充当二级间接块,当数据块数大于NDIRECT+NINDIRECT时,以后的DBL_INDIRECT块会在ip->addrs[NDIRECT+1]的间接块的间接块中列出。
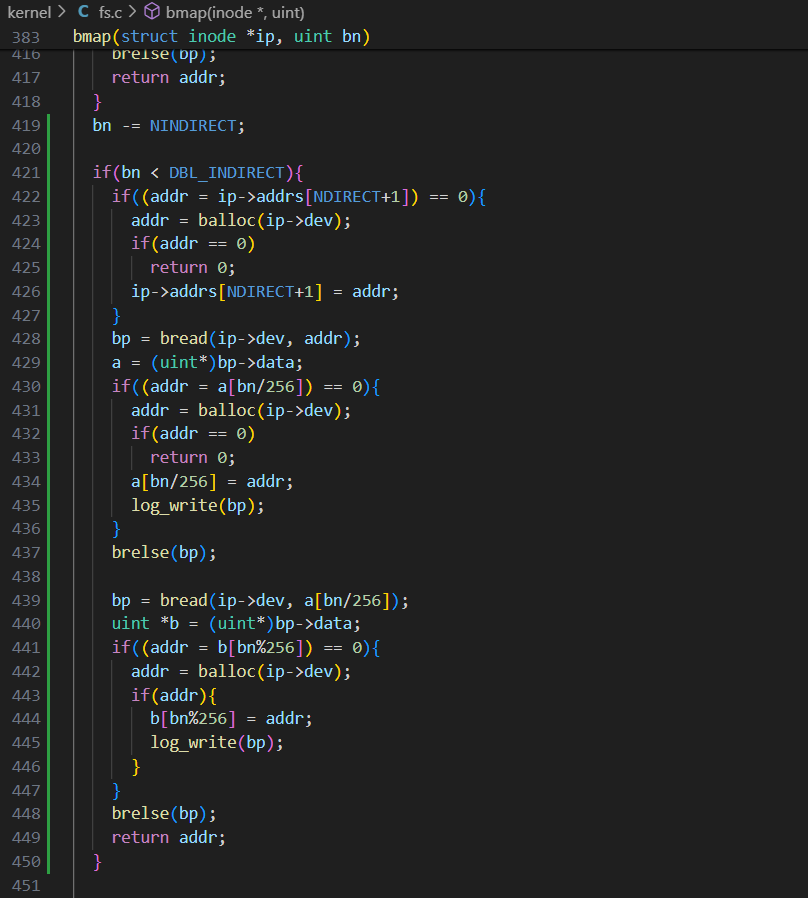
可以仿写一级间接块的实现思路,分配一个二级间接块,将地址存入addrs[NDIRECT+1],二级间接块的内容可看成NINDIRECT个一级间接块的地址组成的address数组,检查二级间接块的每一个元素是否分配了磁盘块,没有则分配一个,当作一级间接块,每个一级间接块中的内容也可看作NINDIRECT个数据块地址组成的address数组,检查每个一级间接块的每一个元素是否分配磁盘块,没有则分配一个,修改代码如下:
kernel/fs.c
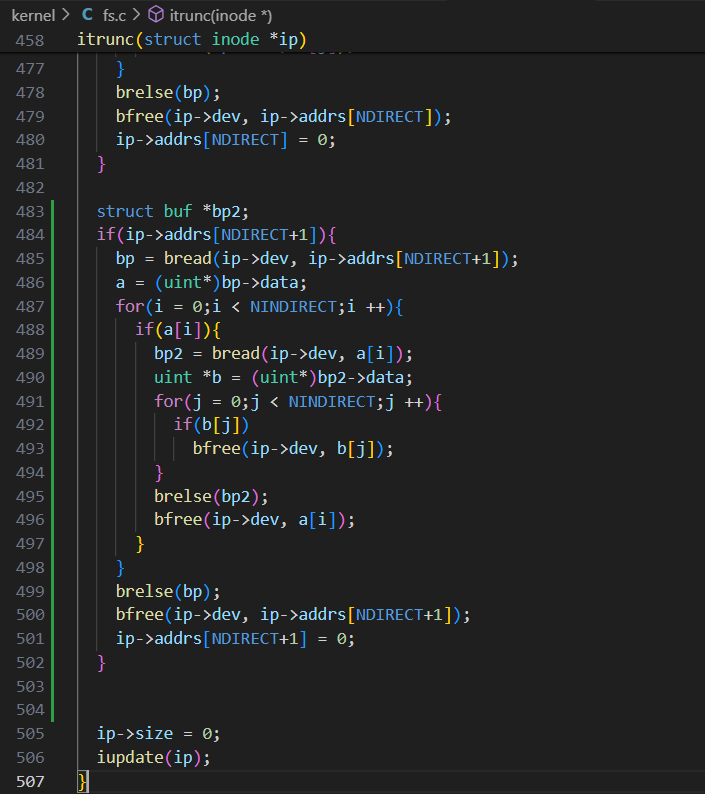
3) 修改 fs.c/itrunc() , itrunc() ⽤于删除整个⽂件内容,则需要查找 inode ,删除所占有的所有数据块,包括⼀级间接块、⼆级间接块。可仿写一级间接块的删除,将二级间接块看成一个数组,遍历二级间接块的每一个元素,将每一个元素看成一个一级间接块,而一个一级间接块也可看成一个数组,删除其中的每一个元素后再删除这个一级间接块,最后将二级间接块删除即可,代码如下:
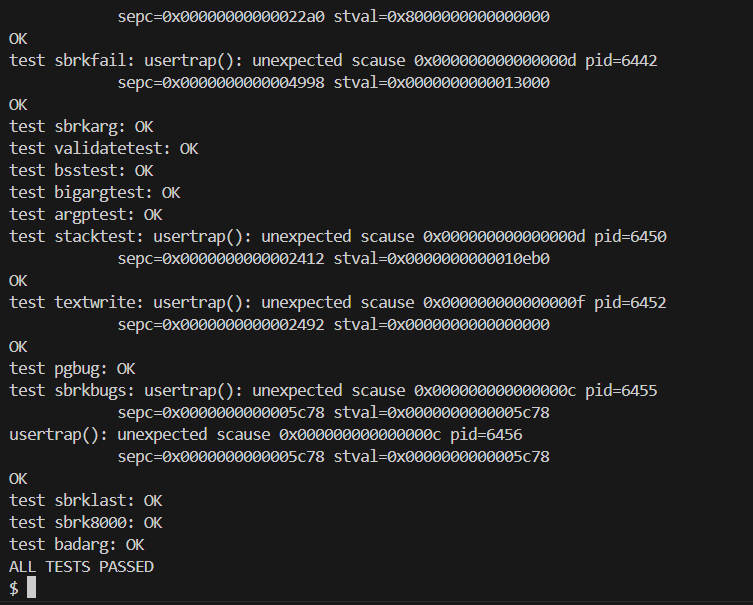
实验结果
bigfile

usertests
二、符号链接功能的支持
本任务将为 xv6 添加符号链接。符号链接(或软链接)通过路径名指向被链接的⽂件;打开符号链接时,内核会根据链接指向被引⽤的⽂件。你需要实现⼀个 symlink(char *target, char *path) 系统调⽤,该调⽤会在 path 处创建⼀个新的符号链接,并指向以 target 命名的⽂件。
提⽰:
⾸先,为 symlink 创建⼀个新的系统调⽤号,在kernel/syscall.h 和 kernel/syscall.c 中添加⼀个系统调⽤,并在 kernel/sysfile.c 中实现⼀个空的 sys_symlink 。然后,并在user/usys.pl 和 user/user.h 中添加⼀个系统调⽤条⽬ int symlink(const char*, const char*) 。
在 kernel/stat.h 中添加新的⽂件类型 (T_SYMLINK) 以表⽰符号链接。
在 kernel/fcntl.h 中添加⼀个新标志 (O_NOFOLLOW) ,该标志位可以与 open 系统调⽤⼀起使⽤。需要注意的是,传递给 open 的标志是通过⽐特 OR 运算符 组合⽽成的,因此新标志不应与任何现有标志重叠。 在 Makefile 中添加$U/_symlinktest\ 到 UPROGS 后,就可以编译它了。
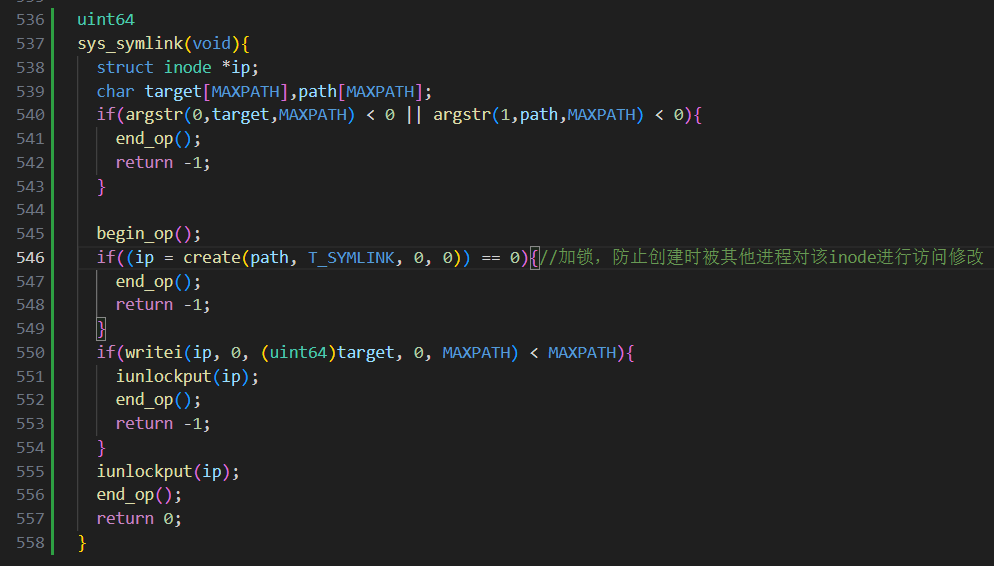
在 kernel/sysfile.c 实现 uint64 sys_symlink(void) 系统调⽤,利⽤函数argstr 获 取系统调⽤的参数 target 和 path ,实现在 path 处创建指向 target 的新符号链接。请注意, 1 )在每⼀个⽂件相关的系统调⽤开始和结束部分需要使⽤begin_op() 和end_op() ,参考 sys_mknod 和 sys_chdir 等系统调⽤的实现⽅法。 2 ) sys_symlink 成功时, target 并不需要存在。 3 )你需要想办法在符号链接中保存 target ,例如,存储在 inode 中的数据块?这样的话,需要⽤到 writei 函数。 4) sys_symlink 应返回⼀个代表成功( 0 )或失败( -1 )的整数,这与 link 和 unlink 类似。
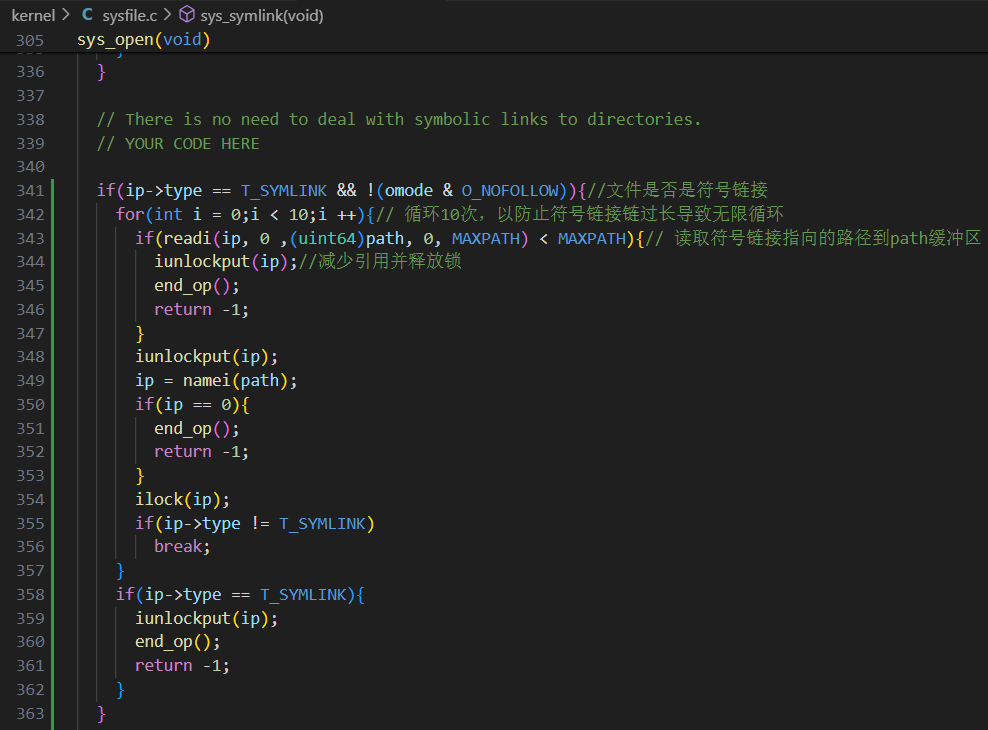
在 k ernel/sysfile.c 修改 unit64 sys_open(void) 系统调⽤,以处理路径指向符号链 接的情况。如果⽂件不存在, open 必须失败。当进程在打开标志中指定 O_NOFOLLOW 时, open 应打开符号链接(⽽不是跟随符号链接)。
如果链接⽂件也是符号链接,则必须递归跟踪,直到找到⾮链接⽂件。如果链接形成循环,则必须返回错误代码。如果链接深度达到某个阈值(如 10 ),则可以通过返回错误代码来近似处理。
注意:本实验不需要处理⽬录的符号链接。
实现过程
添加系统调用号
kernel/syscall.h
添加系统调用
kernel/syscall.c



sysfile.c中先添加一个空的sys_symlink
kernel/stat.h
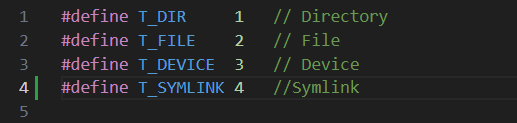
kernel/fcntl.h
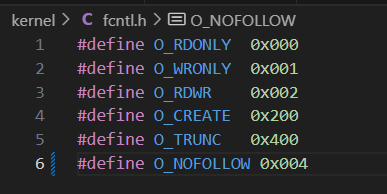
Makefile

sys_symlink系统调用
参考 sys_mknod 和 sys_chdir 等系统调⽤的实现⽅法,从trampframe中取出a0,a1寄存器中的内容,传给target,path字符数组(用于存储目标路径和符号链接路径),创建一个符号链接文件,接着将将目标路径写入新创建的符号链接文件,代码如下:
kernel/sysfile.c
修改sys_open系统调用,添加对符号链接的处理,如果是符号链接则读取符号链接指向的路径path,根据path获得新的inode信息,如果新的inode仍然是符号链接,则递归上述过程,直到找到非链接文件。如果链接深度达到某个阈值(如 10 ),则可以通过返回错误代码来近似处理。代码如下:
kernel/sysfile.c
实验结果
三、实验总结与感想
了解了xv6中的文件系统的实现,学会了如何在xv6中添加大文件功能和符号链接功能,为之后的操作系统学习打下基础。